Jonathanliu92251.github.io
study memo
Project maintained by Jonathanliu92251 Hosted on GitHub Pages — Theme by mattgraham
LinuxFoundationX: LFS158x
Introduction to Kubernetes
Table of Contents
Chapter 1. Container Orchestration
Chapter 2. Kubernetes
Chapter 3. Kubernetes Architecture - Overview
Chapter 4. Installing Kubernetes
Chapter 5. Setting Up a Single-Node Kubernetes Cluster with Minikube
Chapter 6. Accessing Minikube
Chapter 7. Kubernetes Building Blocks
Chapter 8. Authentication, Authorization, Admission Control
Chapter 9. Services
Chapter 10. Deploying a Stand-Alone Application
Chapter 11. Kubernetes Volume Management
Chapter 12. Deploying a Multi-Tier Application
Chapter 13. ConfigMaps and Secrets
Chapter 14. Ingress
Chapter 15. Advanced Topics - Overview
Chapter 16. Kubernetes Community
Chapter 1. Container Orchestration
Objectives:
- Define the concept of container orchestration.
- Explain the reasons for doing container orchestration.
- Discuss different container orchestration options.
- Discuss different container orchestration deployment options.
1. What Are Containers?
an application-centric way to deliver high-performing, scalable applications on the infrastructure of your choice.
With a container image, we bundle the application along with its runtime and dependencies. We use that image to create an isolated executable environment, also known as container. We can deploy containers from a given image on the platform of our choice, such as desktops, VMs, cloud, etc.
2. What Is Container Orchestration?
Container orchestrators are the tools which group hosts together to form a cluster, and help us fulfill the requirements:
- Are fault-tolerant
- Can scale, and do this on-demand
- Use resources optimally
- Can discover other applications automatically, and communicate with each other
- Are accessible from the external world
- Can update/rollback without any downtime.
Nowadays, there are many container orchestrators available, such as:
- Docker Swarm
Docker Swarm is a container orchestrator provided by Docker, Inc. It is part of Docker Engine. - Kubernetes
Kubernetes was started by Google, but now, it is a part of the Cloud Native Computing Foundation project. - Mesos Marathon
Marathon is one of the frameworks to run containers at scale on Apache Mesos. - Amazon ECS
Amazon EC2 Container Service (ECS) is a hosted service provided by AWS to run Docker containers at scale on its infrastructrue. - Hashicorp Nomad
Nomad is the container orchestrator provided by HashiCorp.
Container orchestrators can make things easy for operators:
- Bring multiple hosts together and make them part of a cluster
- Schedule containers to run on different hosts
- Help containers running on one host reach out to containers running on other hosts in the cluster
- Bind containers and storage
- Bind containers of similar type to a higher-level construct, like services, so we don’t have to deal with individual containers
- Keep resource usage in-check, and optimize it when necessary
- Allow secure access to applications running inside containers.
Chapter 2. Kubernetes
Objectives:
- Define Kubernetes.
- Explain the reasons for using Kubernetes.
- Discuss the features of Kubernetes.
- Discuss the evolution of Kubernetes from Borg.
- Explain what the Cloud Native Computing Foundation does.
1. Background
- Cloud Native Computing Foundation (CNCF), which currently hosts the Kubernetes project, along with other cloud-native projects
- Kubernetes comes from the Greek word κυβερνήτης:, which means helmsman or ship pilot. With this analogy in mind, we can think of Kubernetes as the manager for shipping containers.
- Kubernetes was started by Google and, with its v1.0 release in July 2015, Google donated it to the Cloud Native Computing Foundation (CNCF).
2. Kubernetes features
- Automatic binpacking
Kubernetes automatically schedules the containers based on resource usage and constraints, without sacrificing the availability. - Self-healing
Kubernetes automatically replaces and reschedules the containers from failed nodes. It also kills and restarts the containers which do not respond to health checks, based on existing rules/policy. - Horizontal scaling
Kubernetes can automatically scale applications based on resource usage like CPU and memory. In some cases, it also supports dynamic scaling based on customer metrics. - Service discovery and Load balancing
Kubernetes groups sets of containers and refers to them via a Domain Name System (DNS). This DNS is also called a Kubernetes service. Kubernetes can discover these services automatically, and load-balance requests between containers of a given service. - Automated rollouts and rollbacks
Kubernetes can roll out and roll back new versions/configurations of an application, without introducing any downtime. - Secrets and configuration management
Kubernetes can manage secrets and configuration details for an application without re-building the respective images. With secrets, we can share confidential information to our application without exposing it to the stack configuration, like on GitHub. - Storage orchestration
With Kubernetes and its plugins, we can automatically mount local, external, and storage solutions to the containers in a seamless manner, based on software-defined storage (SDS). - Batch execution
Besides long running jobs, Kubernetes also supports batch execution. - Portable and extensible
Kubernetes can be deployed on the environment of our choice, be it VMs, bare metal, or public/private/hybrid/multi-cloud setups. Also, Kubernetes has a very modular and pluggable architecture. We can write custom APIs or plugins to extend its functionalities.
Chapter 3. Kubernetes Architecture - Overview
Objectives:
- Discuss the Kubernetes architecture.
- Explain the different components for master and worker nodes.
- Discuss about cluster state management with etcd.
- Review the Kubernetes network setup requirements.
#Chapter 4. Installing Kubernetes Objectives:
- Discuss about the different Kubernetes configuration options.
- Discuss infrastructure considerations before installing Kubernetes.
- Discuss infrastructure choices for a Kubernetes deployment.
- Review Kubernetes installation tools and resources.
1. Installation
- Localhost Installation
- Minikube
- Ubuntu on LXD.
- On-Premise Installation
- On-Premise VMs. Kubernetes can be installed on VMs created via Vagrant, VMware vSphere, KVM, etc. There are different tools available to automate the installation, like Ansible or kubeadm.
- On-Premise Bare Metal.
- Kubernetes can be installed on on-premise bare metal, on top of different operating systems, like RHEL, CoreOS, CentOS, Fedora, Ubuntu, etc. Most of the tools used to install VMs can be used with bare metal as well.
- Cloud Installation
- Google Kubernetes Engine (GKE)
- Azure Container Service (AKS)
- Amazon Elastic Container Service for Kubernetes (EKS) - Currently in Tech Preview
- OpenShift Dedicated
- Platform9
- IBM Cloud Container Service.
- Turnkey Cloud Solutions
- Google Compute Engine
- Amazon AWS
- Microsoft Azure
- Tectonic by CoreOS.
- Bare Metal ( Cloud )
Chapter 5. Setting Up a Single-Node Kubernetes Cluster with Minikube
Objectives:
- Discuss Minikube.
- Install Minikube on Linux, Mac, and Windows.
- Verify the installation.
Chapter 6. Accessing Minikube
Objectives:
- Review methods to access any Kubernetes cluster.
- Configure kubectl for Linux, macOS, and Windows.
- Access the Minikube dashboard.
- Access Minikube via APIs.
Chapter 7. Kubernetes Building Blocks
Objectives:
- Review the Kubernetes object model.
- Discuss Kubernetes building blocks, e.g. Pods, ReplicaSets, Deployments, Namespaces.
- Discuss Labels and Selectors.
1. Pod
- Pods are ephemeral in nature, and they do not have the capability to self-heal by themselves.
- That is why we use them with controllers, which can handle a Pod’s replication, fault tolerance, self-heal, etc.
- Examples of controllers are Deployments, ReplicaSets, ReplicationControllers, etc.
- We attach the Pod’s specification to other objects using Pods Templates, as we have seen in the previous section.
2. Label
- Labels are key-value pairs that can be attached to any Kubernetes objects (e.g. Pods).
- Labels are used to organize and select a subset of objects, based on the requirements in place.
- Many objects can have the same Label(s). Labels do not provide uniqueness to objects.
- Equality-Based Selectors. =, ==, or != operators. For example, env==dev
- Set-Based Selectors, the in, notin, and exist operators. For example, with env in (dev,qa)
3. ReplicationController
- A ReplicationController (rc) is a controller that is part of the master node’s controller manager. It makes sure the specified number of replicas for a Pod is running at any given point in time.
- Generally, we don’t deploy a Pod independently, as it would not be able to re-start itself, if something goes wrong.
- We always use controllers like ReplicationController to create and manage Pods.
4. ReplicaSet
- A ReplicaSet (rs) is the next-generation ReplicationController. ReplicaSets support both equality- and set-based selectors,
- whereas ReplicationControllers only support equality-based Selectors.
- ReplicaSets can be used independently, but they are mostly used by Deployments to orchestrate the Pod creation, deletion, and updates.
- A Deployment automatically creates the ReplicaSets, and we do not have to worry about managing them.
5. Deployment
- Deployment objects provide declarative updates to Pods and ReplicaSets. The DeploymentController is part of the master node’s controller manager,
- and it makes sure that the current state always matches the desired state.
- A rollout is only triggered when we update the Pods Template for a deployment.
- Operations like scaling the deployment do not trigger the deployment.
6. Namespaces
Chapter 8. Authentication, Authorization, Admission Control
Objectives:
- Discuss authentication, authorization, and access control stages of the Kubernetes API access.
- Understand the different kinds of Kubernetes users.
- Explore the different modules for authentication and authorization.
1. Concepts
- Authentication
Logs in a user. - Authorization
Authorizes the API requests added by the logged-in user. - Admission Control
Software modules that can modify or reject the requests based on some additional checks, like Quota. –admission-control=NamespaceLifecycle, ResourceQuota, PodSecurityPolicy, DefaultStorageClass.
2. Kubernetes Users
- Normal Users.
They are managed outside of the Kubernetes cluster via independent services like User/Client Certificates, a file listing usernames/passwords, Google accounts, etc. - Service Accounts.
With Service Account users, in-cluster processes communicate with the API server to perform different operations. Most of the Service Account users are created automatically via the API server, but they can also be created manually. The Service Account users are tied to a given Namespace and mount the respective credentials to communicate with the API server as Secrets. - Anonymous.
If properly configured, Kubernetes can also support anonymous requests, along with requests from Normal Users and Service Accounts.
3. Authentication Methods
- Client Certificates.
To enable client certificate authentication, we need to reference a file containing one or more certificate authorities by passing the –client-ca-file=SOMEFILE option to the API server. The certificate authorities mentioned in the file would validate the client certificates presented to the API server. A demonstration video covering this topic is also available at the end of this chapter. - Static Token File.
We can pass a file containing pre-defined bearer tokens with the –token-auth-file=SOMEFILE option to the API server. Currently, these tokens would last indefinitely, and they cannot be changed without restarting the API server. - Bootstrap Tokens.
This feature is currently in an alpha status, and is mostly used for bootstrapping a new Kubernetes cluster. - Static Password File.
It is similar to Static Token File. We can pass a file containing basic authentication details with the –basic-auth-file=SOMEFILE option. These credentials would last indefinitely, and passwords cannot be changed without restarting the API server. - Service Account Tokens.
This is an automatically enabled authenticator that uses signed bearer tokens to verify the requests. These tokens get attached to Pods using the ServiceAccount Admission Controller, which allows in-cluster processes to talk to the API server. - OpenID Connect Tokens.
OpenID Connect helps us connect with OAuth 2 providers, such as Azure Active Directory, Salesforce, Google, etc., to offload the authentication to external services. - Webhook Token Authentication.
With Webhook-based authentication, verification of bearer tokens can be offloaded to a remote service. - Keystone Password.
Keystone authentication can be enabled by passing the –experimental-keystone-url=option to the API server, where AuthURL is the Keystone server endpoint. - Authenticating Proxy.
If we want to program additional authentication logic, we can use an authenticating proxy.
Chapter 9. Services
Objectives:
- Discuss the benefits of grouping Pods into Services to access an application.
- Explain the role of the kube-proxy daemon running on each worker node.
- Explore the Service discovery options available in Kubernetes.
- Discuss different Service types.
1. Service
p{ white-space:pre-wrap;}
Kubernetes provides a higher-level abstraction called Service, which logically groups Pods and a policy to access them. This grouping is achieved via Labels and Selectors, which we talked about in the previous chapter.
 2. kube-proxy
2. kube-proxy
All of the worker nodes run a daemon called kube-proxy, which watches the API server on the master node for the addition and removal of Services and endpoints. For each new Service, on each node, kube-proxy configures the iptables rules to capture the traffic for its ClusterIP and forwards it to one of the endpoints. When the service is removed, kube-proxy removes the iptables rules on all nodes as well.
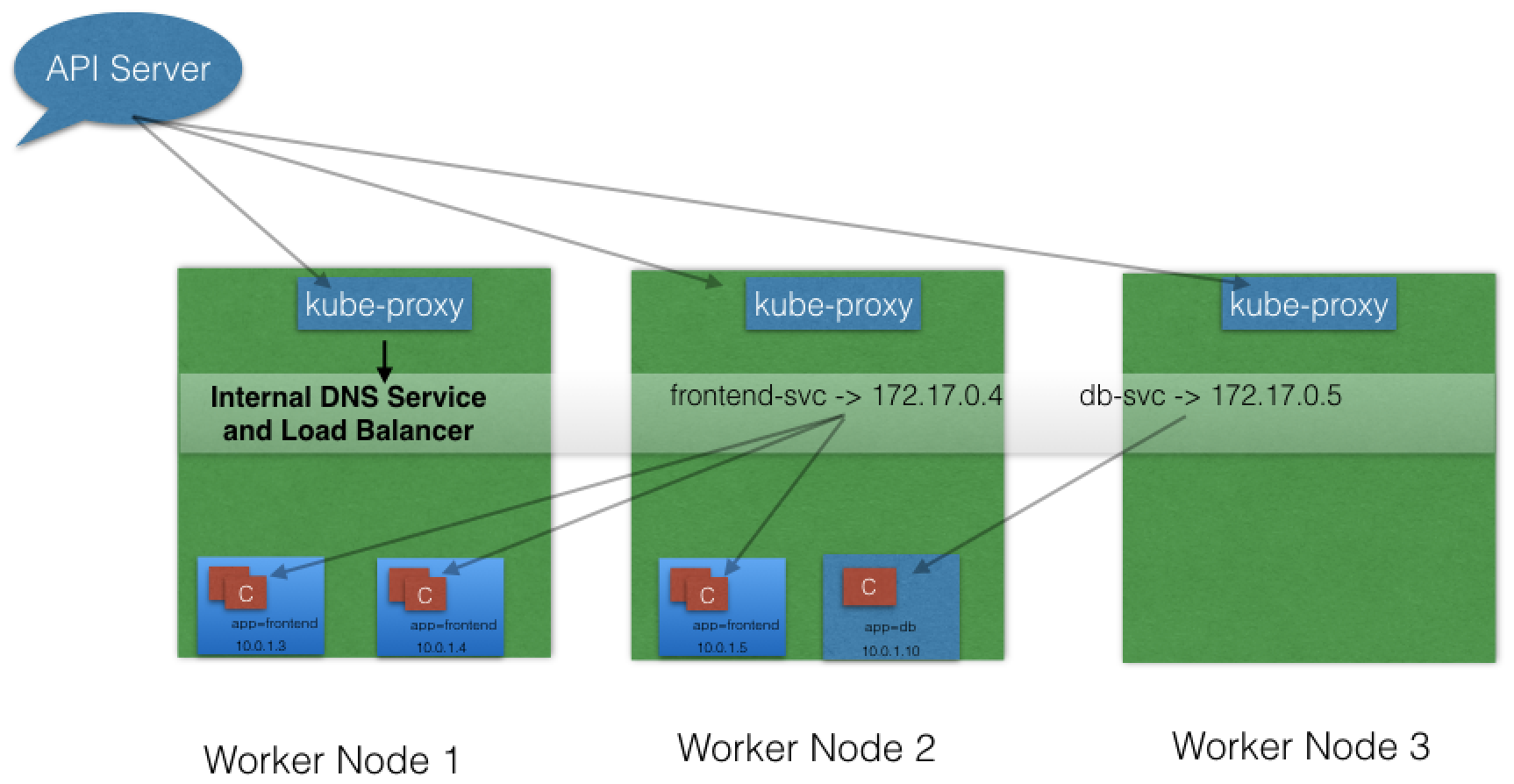
3. Service Discovery
- Environment Variables
- DNS add-on
4. ServiceType
- ClusterIP
is the default ServiceType. A Service gets its Virtual IP address using the ClusterIP. - NodePort
in addition to creating a ClusterIP, a port from the range 30000-32767 is mapped to the respective Service, from all the worker nodes. The end-user connects to the worker nodes on the specified port, which forwards the traffic to the applications running inside the cluster. - LoadBalancer (specific vendor support)
- NodePort and ClusterIP Services are automatically created, and the external load balancer will route to them
- The Services are exposed at a static port on each worker node
- The Service is exposed externally using the underlying cloud provider’s load balancer feature.
- ExternalIP (specific vendor support) Traffic that is ingressed into the cluster with the ExternalIP (as destination IP) on the Service port, gets routed to one of the the Service endpoints.
- ExternalName (specific vendor support)
configured Services like my-database.example.com available inside the cluster, using just the name, like my-database, to other Services inside the same Namespace.
Chapter 10. Deploying a Stand-Alone Application
Objectives:
- Deploy an application from the dashboard.
- Deploy an application from a YAML file using kubectl.
- Expose a service using NodePort.
- Access the application from the external world.
1. Deploy Application
-
Deploying an Application Using the Minikube GUI
-
Deploying the Application Using the CLI
Step 1. Create a YAML file with Deployment details
apiVersion: apps/v1 kind: Deployment metadata: name: webserver labels: app: nginx spec: replicas: 3 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:alpine ports: - containerPort: 80
Step 2. Creating a Service and Exposing It to the External World with NodePort
Step 3. Create a webserver-svc.yaml file with the following content:
apiVersion: v1 kind: Service metadata: name: web-service labels: run: web-service spec: type: NodePort ports: - port: 80 protocol: TCP selector: app: nginx
** 2. Liveness and Readiness Probes **
Liveness probe checks on an application’s health, and, if for some reason, the health check fails, it restarts the affected container automatically.
Sometimes, applications have to meet certain conditions before they can serve traffic. These conditions include ensuring that the depending service is ready, or acknowledging that a large dataset needs to be loaded, etc. In such cases, we use Readiness Probes and wait for a certain condition to occur. Only then, the application can serve traffic.
Chapter 11. Kubernetes Volume Management
Objectives:
- Explain the need for persistent data management.
- Discuss Kubernetes Volume and its types.
- Discuss PersistentVolumes and PersistentVolumeClaims.
1. Volume Types
- emptyDir
An empty Volume is created for the Pod as soon as it is scheduled on the worker node. The Volume’s life is tightly coupled with the Pod. If the Pod dies, the content of emptyDir is deleted forever. - hostPath
With the hostPath Volume Type, we can share a directory from the host to the Pod. If the Pod dies, the content of the Volume is still available on the host. - gcePersistentDisk
With the gcePersistentDisk Volume Type, we can mount a Google Compute Engine (GCE) persistent disk into a Pod. - awsElasticBlockStore
With the awsElasticBlockStore Volume Type, we can mount an AWS EBS Volume into a Pod. - nfs
With nfs, we can mount an NFS share into a Pod. - iscsi
With iscsi, we can mount an iSCSI share into a Pod. - secret
With the secret Volume Type, we can pass sensitive information, such as passwords, to Pods. We will take a look at an example in a later chapter. - persistentVolumeClaim
We can attach a PersistentVolume to a Pod using a persistentVolumeClaim.
2. PersistentVolumes
A Persistent Volume is a network-attached storage in the cluster, which is provisioned by the administrator.
PersistentVolumes can be dynamically provisioned based on the StorageClass resource. A StorageClass contains pre-defined provisioners and parameters to create a PersistentVolume. Using PersistentVolumeClaims, a user sends the request for dynamic PV creation, which gets wired to the StorageClass resource.
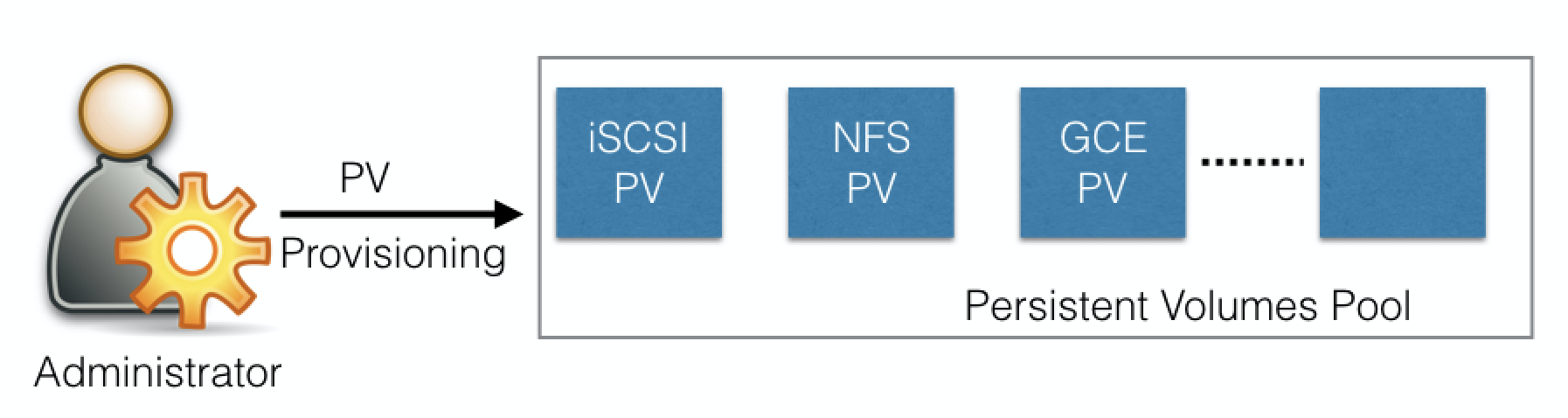
3. PersistentVolumeClaims
A PersistentVolumeClaim (PVC) is a request for storage by a user. Users request for PersistentVolume resources based on size, access modes, etc. Once a suitable PersistentVolume is found, it is bound to a PersistentVolumeClaim.
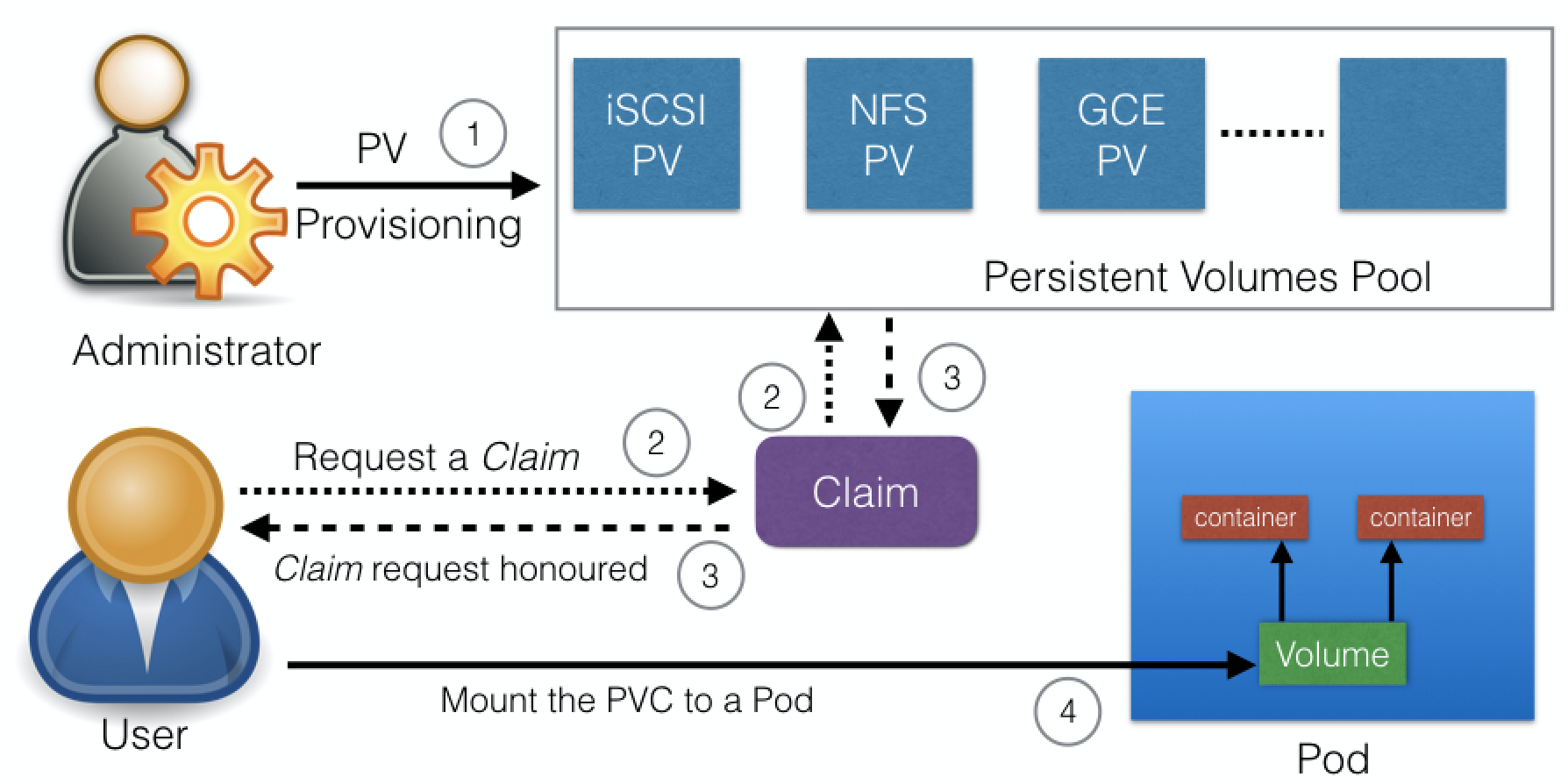 Once a user finishes its work, the attached PersistentVolumes can be released. The underlying PersistentVolumes can then be reclaimed and recycled for future usage.
Once a user finishes its work, the attached PersistentVolumes can be released. The underlying PersistentVolumes can then be reclaimed and recycled for future usage.
4. Container Storage Interface (CSI)
third-party storage providers can develop solutions without the need to add them into the core Kubernetes codebase.
Chapter 12. Deploying a Multi-Tier Application
Objectives:
- Analyze a sample multi-tier application.
- Deploy a multi-tier application.
- Scale an application.
# Chapter 13. ConfigMaps and Secrets Objectives:
- Discuss configuration management for applications in Kubernetes using ConfigMaps.
- Share sensitive data (such as passwords) using Secrets.
1. ConfigMaps
ConfigMap, pass such runtime parameters like configuration details.
Secret, when we want to pass sensitive information.
Decouple the configuration details from the container image. Using ConfigMaps, we can pass configuration details as key-value pairs, which can be later consumed by Pods, or any other system components, such as controllers.
A ConfigMap can be created with the kubectl create command, and we can get the values using the kubectl get command.
$ kubectl create configmap my-config --from-literal=key1=value1 --from-literal=key2=value2
$ kubectl get configmaps my-config -o yaml
As a Volume We can mount a ConfigMap as a Volume inside a Pod. For each key, we will see a file in the mount path and the content of that file becomes the respective key’s value
2. Secrets
we can share sensitive information like passwords, tokens, or keys in the form of key-value pairs, similar to ConfigMaps;
In Deployments or other system components, the Secret object is referenced, without exposing its content. the Secret data is stored as plain text inside etcd.
$ kubectl create secret generic my-password --from-literal=password=mysqlpassword
$ kubectl get secret my-password
$ kubectl describe secret my-password
Chapter 14. Ingress
Objectives:
- Explain what Ingress and Ingress Controllers are.
- Learn when to use Ingress.
- Access an application from the external world using Ingress.
1. Concepts
“An Ingress is a collection of rules that allow inbound connections to reach the cluster Services.”
Ingress configures a Layer 7 HTTP load balancer for Services and provides the following:
- TLS (Transport Layer Security)
- Name-based virtual hosting
- Path-based routing
- Custom rules.
2. Example
An Ingress Controller is an application which watches the Master Node’s API server for changes in the Ingress resources and updates the Layer 7 Load Balancer accordingly.
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: web-ingress
namespace: default
spec:
rules:
- host: blue.example.com
http:
paths:
- backend:
serviceName: webserver-blue-svc
servicePort: 80
- host: green.example.com
http:
paths:
- backend:
serviceName: webserver-green-svc
servicePort: 80
$ kubectl create -f webserver-ingress.yaml
$ cat /etc/hosts
127.0.0.1 localhost
::1 localhost
192.168.99.100 blue.example.com green.example.com

# Chapter 15. Advanced Topics
1. Annotations
In contrast to Labels, annotations are not used to identify and select objects. With Annotations, we can attach arbitrary non-identifying metadata to any objects, in a key-value format:Annotations can be used to:
- Store build/release IDs, PR numbers, git branch, etc.
- Phone/pager numbers of people responsible, or directory entries specifying where such information can be found
- Pointers to logging, monitoring, analytics, audit repositories, debugging tools, etc.
2. Deployment Features
- Recording a Deployment - if something goes wrong, we can revert to the working state.
- Autoscaling
- Proportional scaling
- Pausing and resuming.
3. Jobs
Such as cron jobs.
A Job creates one or more Pods to perform a given task. The Job object takes the responsibility of Pod failures. It makes sure that the given task is completed successfully. Once the task is over, all the Pods are terminated automatically.
4. Quota Management
quotas per Namespace
- Compute Resource Quota
We can limit the total sum of compute resources (CPU, memory, etc.) that can be requested in a given Namespace. - Storage Resource Quota
We can limit the total sum of storage resources (PersistentVolumeClaims, requests.storage, etc.) that can be requested. - Object Count Quota
We can restrict the number of objects of a given type (pods, ConfigMaps, PersistentVolumeClaims, ReplicationControllers, Services, Secrets, etc.).
5. DaemonSets
6. StatefulSets
7. Kubernetes Federation
8. Custom Resources
9. Helm
- Chart. We can bundle all those manifests after templatizing them into a well-defined format, along with other metadata.
- Helm is a package manager for Kubernetes, which can install/update/delete those Charts in the Kubernetes cluster.
- A client called helm, which runs on your user’s workstation
- A server called tiller, which runs inside your Kubernetes cluster.
10. Monitoring and Logging
- Heapster is a cluster-wide aggregator of monitoring and event data
- Prometheus, can also be used to scrape the resource usage from different Kubernetes components and objects. Using its client libraries, we can also instrument the code of our application.
- Elasticsearch, ollect the logs from different components of a given system
- fluentd is an open source data collector, with custom configuration as an agent on the nodes.
Chapter 16. Kubernetes Community
Kubernetes 常用命令
命令 | 解释
—-|—–
Kubernetes命令行 – 集群状态 |
kubectl cluster-info | 查看集群信息
kubectl version | 显示kubectl命令行及kube服务端的版本
kubectl api-version | 显示支持的API版本集合
kubectl config view | 显示当前kubectl配置
kubectl get no | 查看集群中节点
Kubernetes命令行 – 创建新资源 |
kubectl create -f